

Algorithm development for existing defences of adversarial attacks and their difficulties
In Brief
- Futuristic Artificial Intelligence approaches are very efficient in terms of technology, however they are easily susceptible to Adversarial attacks
- Adversarial attacks are a major problem to Intrusion Detection Systems since they are difficult to implement.
- The existing defences are reviewed in brief and the difficulties faced are listed out
- It is necessary to identify feasible and effective solutions for providing security against the attack.
Background
Adversarial attacks are inputs introduced deliberately to a model by attackers to corrupt the detection process (Wang, Li, Kuang, Tan, & Li, 2019).
For more details on introduction to Adversarial attacks, see;Recent Challenges in Artificial Intelligence – Adversarial Attacks
The models are tricked into thinking that the object is something else (S. Chen et al., 2018). It is very difficult to detect and there have been attempts to improve the detection accuracy of these attacks. It is difficult to create models theoretically for crafting the adversarial processes. Since there are no available models for optimising this problem, it makes detection of these kinds of attack very difficult (Iglesias, Milosevic, & Zseby, 2019).

There are no available models for optimising this problem, it makes detection of these kinds of attack very difficult (Iglesias, Milosevic, & Zseby, 2019)
The machine learning approaches must create very good outputs and must perform very well for efficient detection of adversarial attacks. Most of the available techniques are hence not very effective in predicting the adversarial attacks even though they are very efficient in detecting ordinary attacks. Hence, it is necessary to create an effective defence approach for the adversarial attacks. There are some available defensive mechanisms against these attacks
Adversarial training is an approach where lots of adversarial examples are generated by the users in order to train the algorithm. Hence, this is a type of brute force solution where these extensive adversarial data is trained for classifying the attack accurately. However, these can be broken down easily; therefore the attacker can exploit the network easily.Most of the available techniques are hence not very effective in predicting the adversarial attacks even though they are very efficient in detecting ordinary attacks.
The problems with the existing techniques is that the modifications occur with respect to perturbations such that they are linearly proportional to the modified pixel values (Ozdag, 2018). It is seen that newer machine learning techniques can be compromised in unprecedented ways. Even simple inputs may break the techniques leading to abnormal behaviour of the algorithms.
To show how the defences fail easily, let us consider with respect to gradient masking. This is used in black box applications against deep learning systems (J. Chen, Su, Shen, Xiong, & Zheng, 2019). Most of the adversarial attacks use gradients of the model for assisting the attacks. The model looks at a picture and check which space looks more like another object and boost that location to misrecognize the entire picture as the new image.
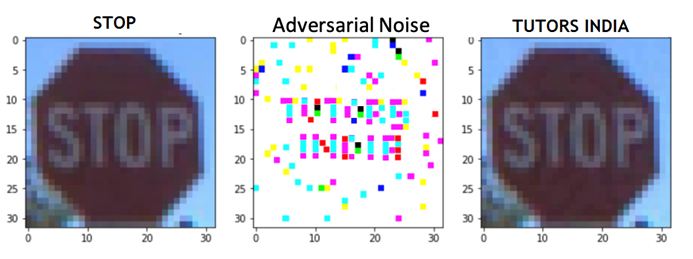
Figure 1: Adversarial attack using gradients
In figure 1, the sign reads ‘STOP’. The attacker identifies the location of the letters which will be used for the detection. In that location adversarial noise is supplied in the identified location to overlap on the STOP letters. Hence the sign will be read as ‘PHD ASSISTANCE’.
However, since there is availability of gradient, the attack is possible. If there is no gradient in the image, then even when the image is modified using the adversarial attack, there will not be any change in the detection type. Hence, images without gradients can be maintained in order to eliminate these attacks.
Most image classification models classify the output with the part where they mostly fall under and where they have the highest probability. If the output specifies 90% as STOP and 9.9% as other texts and 0.1% as PHD ASSISTANCE, then models can tell us the location of pixels change that will increase the probability of classification as PhD Assistance. Hence, these pixels are modified in such a way that we can eliminate those related texts completely; hence there will be 0% of classifying it as PhD Assistance.
Now, when we run the model as the most likely class and not probabilistic model, then the attacker will not able to identify the inputs and location to modify the text. This gives the user some defence against the adversarial attacks. However, this method is not fool-proof and not 100% efficient. It only reduces the clues for the attacker to figure out and makes it harder to identify the points (Huang, Papernot, Goodfellow, Duan, & Abbeel, 2017). The model must be improved to give 100% accurate defence. If the attacker uses their own gradients for the images, then they can identify the location and initiate the attack.
Future Defence Possibilities
These defence strategies which are used in the gradient masking usually lead to smooth models with respect to the training points which make it very difficult for the adversary attacks to identify the gradients which is a good indicators that the input cannot perturb properly and damage the images. However, the attack may train alternate models which imitates the security model by looking at the labels which are assigned to the input and these inputs are used by the attackers to plan the attack.
Such attacks were performed in the literature using black box attacks (Papernot, McDaniel, Goodfellow, et al., 2016; Sadeghi & Larsson, 2019). The attacker can use the gradients of the alternate models for identifying the misclassification security in the model.
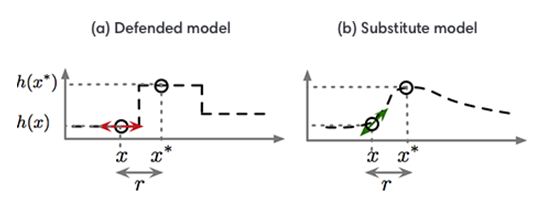
Figure 2: The substitute security model
Source Adopted From: Papernot, McDaniel, Sinha, & Wellman,(2016)
Figure 2 shows the attack strategy used in single dimensional machine learning problem (Papernot, McDaniel, Sinha, et al., 2016). The gradient masking phenomenon can extract the problems in higher dimensions, but difficult to represent. It is seen that the adversarial training performs gradient masking unintentionally. Even though they are not designed for that specifically, they provide limited security when they are trained for defensive stand without providing any specific rules to follow (Kurakin, Goodfellow, & Bengio, 2016). Usually, when the adversarial attacks are transferred to another model, the attack is successful since the second algorithm is not able to adapt to the trained model of the first algorithm. Hence, he gradients must be removed in order to reduce the success of adversarial attacks.
Limitations and future scope for PhD Computer Science Researchers pursuing their research in Adversarial Attacks based on Machine Learning Algorithms Dissertation
Summary and Future Scope
• These attacks are hard to defend since the trained ML / AI models must produce good outputs for all the outputs.
• This is difficult since the models usually make mistakes leading to false positives and true negatives, which must be avoided at all costs to counter the adversarial attacks.
• Almost all the strategies fail since there are not as adaptive to all kinds of attack and focus on few sets of attacks. An anti-adversarial model must be effective for all kinds of attacks.
• The research for adversarial attacks is only at the initial stage and has a huge scope of research for building an effective model for providing security against adversarial attacks.
- Guidelines to Write a Research Proposal for Neurology Research Scholars - March 19, 2021
- How to Choose a PhD Dissertation Topic For Economic Research? List out the Criteria for Topic Selection - March 11, 2021
- Beginners Guide to Write a Research Proposal for a PhD in Computer Science - February 19, 2021